For my current client’s site we realized that our sitemap.xml was indexed by Google, making it appear in our search result. While we want search engines to crawl the sitemap, we do not want it indexed.
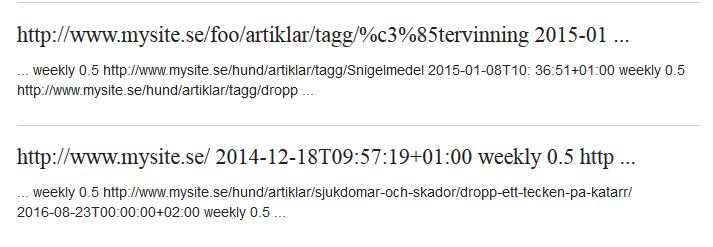
We are currently using a version of the EPiServer sitemap.xml generator described in the article Sitemap.xml generator engine for Multi language EPiServer 7.5 websites as well as Updated sitemap.xml generator functionality with bundle and batch support using sitemapindex.
Remove sitemap.xml from search result with the X-Robots-Tag HTTP Header
The solution is rather simple. Adding a custom HTTP header X-Robots-Tag with value noindex we can ask the crawler not to index the sitemap. This header may also be used on pages that are not XML.
To update the sitemap.xml generator, slight changes need to be made to the XmlActionResult class; we now keep a public Header dictionary (7) and use it to populate the response header collection (25-28).
XmlActionResult.cs
public sealed class XmlActionResult : ActionResult
{
private readonly XmlDocument _document;
public Formatting Formatting { get; set; }
public string MimeType { get; set; }
public Dictionary<string,string> Headers { get; set; }
public XmlActionResult(XmlDocument document)
{
if (document == null) throw new ArgumentNullException("document");
_document = document;
MimeType = "text/xml";
Formatting = Formatting.None;
Headers = Headers ?? new Dictionary<string, string>();
}
public override void ExecuteResult(ControllerContext context)
{
context.HttpContext.Response.Clear();
context.HttpContext.Response.ContentType = MimeType;
context.HttpContext.Response.Expires = 0;
foreach (var header in Headers)
{
context.HttpContext.Response.AddHeader(header.Key, header.Value);
}
using (var writer = new XmlTextWriter(context.HttpContext.Response.OutputStream, Encoding.UTF8) {Formatting = Formatting})
{
_document.WriteTo(writer);
}
}
}
As the response header property does not have a public setter, we’ll simply loop the custom headers and add them one by one.
The SitemapController class itself does also need a bit of updating. The Index action now need to set the header property on our XmlActionResult before returning it (10).
[Route("sitemap.xml")]
public ActionResult Index(int batch = 0, string bundle = "")
{
var language = _contentLanguage.PreferredCulture.IetfLanguageTag;
var selector = new SitemapSelector { Language = language, Bundle = bundle, Batch = batch };
var ms = new MemoryStream(_sitemapRepository.ReadSitemapFor(selector));
var doc = new XmlDocument();
doc.Load(ms);
var headers = new Dictionary<string, string> { { "X-Robots-Tag", "noindex" } };
return new XmlActionResult(doc) { Headers = headers };
}
I suppose you could put those strings in a constant’s file somewhere if you’d like. In any case, this will give you a custom header when surfing to your sitemap.xml address.
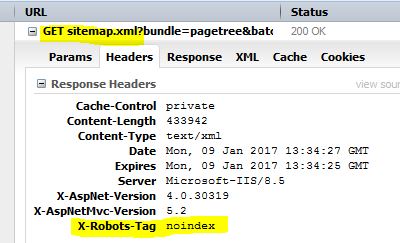
For more information, please see Robots Exclusion Protocol: now with evem more flexibility.